La technologie d'IA de l'Université de Washington permet aux porteurs d'écouteurs de choisir des sons spécifiques à écouter

Une équipe dirigée par des chercheurs en informatique de l'université de Washington (UofW) a créé le logiciel d'intelligence artificielle pour les casques d'écoute qui permettent aux utilisateurs de sélectionner des sons spécifiques à entendre. Contrairement aux casques antibruit qui filtrent tout sauf les voix, le nouveau réseau neuronal permet aux utilisateurs de sélectionner des sons spécifiques tels que le gazouillis d'un oiseau.
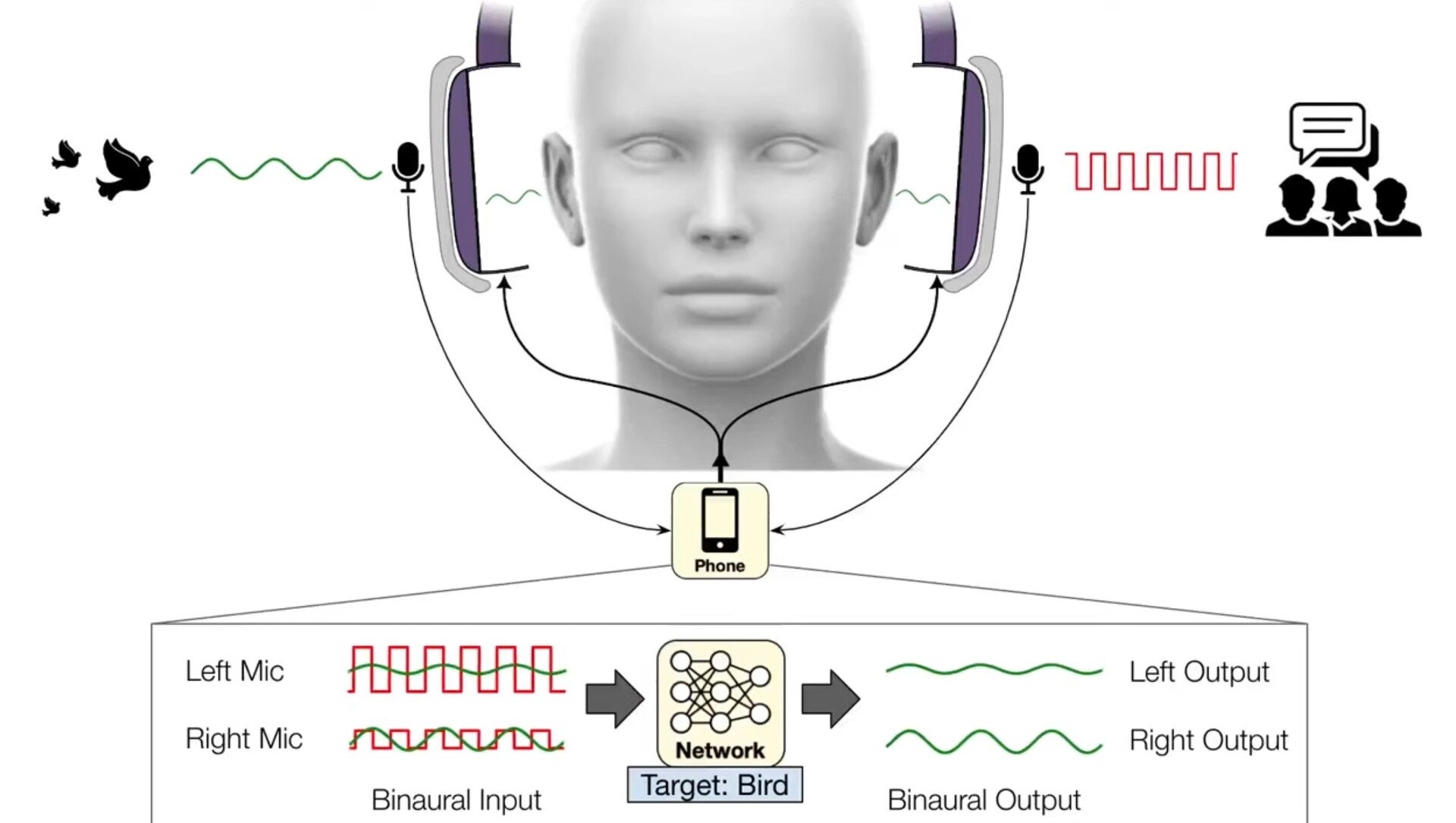
Les casques précédents, tels que les écouteurs Sony INZONE(disponibles sur Amazon), utilisent DSEE Extreme, Speak-to-Chatet AI DNNpour améliorer la qualité de la musique et de la parole tout en laissant automatiquement passer les voix à travers le système de réduction du bruit lorsque les conversations commencent. Les travaux de l'Université de Waterloo vont plus loin en permettant aux auditeurs de choisir parmi 20 types de sons différents, tels que le gazouillis des oiseaux, l'océan, les coups de porte et la chasse d'eau, tout en filtrant le reste. Appelé audition sémantique, ce système permet aux utilisateurs d'apprécier le gazouillis des oiseaux dans un parc sans entendre les gens parler ou les voitures passer.
Actuellement, l'application de l'UofW utilise des microphones binauraux pour capturer la position en temps réel des sons externes avant d'envoyer les sons filtrés vers les écouteurs. Comme ce logiciel fonctionne sur des smartphones, l'application peut exploiter des processeurs plus puissants que ceux des écouteurs, mais ce n'est qu'une question de temps avant que les écouteurs anti-bruit ne soient dotés de l'audition sémantique intégrée.


Source(s)
Université de WashingtonACMet Paul G. Allen School (YouTube)
9 novembre 2023
Une nouvelle technologie d'écouteurs anti-bruit basée sur l'IA permet aux utilisateurs de choisir les sons qu'ils entendent
Stefan Milne
Nouvelles de l'UW
Quiconque a déjà utilisé un casque anti-bruit sait qu'il peut être vital d'entendre le bon bruit au bon moment. Quelqu'un peut vouloir supprimer les klaxons des voitures lorsqu'il travaille à l'intérieur, mais pas lorsqu'il se promène dans des rues animées. Pourtant, il n'est pas possible de choisir les sons que les casques éliminent.
Aujourd'hui, une équipe dirigée par des chercheurs de l'université de Washington a mis au point des algorithmes d'apprentissage profond qui permettent aux utilisateurs de choisir les sons qui filtrent à travers leurs écouteurs en temps réel. L'équipe a baptisé ce système "audition sémantique" Les écouteurs transmettent le son capturé à un smartphone connecté, qui annule tous les sons environnants. Par le biais de commandes vocales ou d'une application pour smartphone, les porteurs de casques peuvent sélectionner les sons qu'ils souhaitent inclure parmi 20 catégories, telles que les sirènes, les pleurs de bébé, la parole, les aspirateurs et les gazouillis d'oiseaux. Seuls les sons sélectionnés seront diffusés par le casque.
L'équipe a présenté ses résultats le 1er novembre à l'occasion de la conférence UIST '23 à San Francisco. À l'avenir, les chercheurs prévoient de lancer une version commerciale du système.
"Comprendre le son d'un oiseau et l'extraire de tous les autres sons d'un environnement nécessite une intelligence en temps réel que les casques antibruit actuels ne parviennent pas à mettre en œuvre", explique l'auteur principal, Shyam Gollakota, professeur à la Paul G. Allen School of Computer Science & Engineering de l'université de Washington. "Le défi réside dans le fait que les sons entendus par les porteurs de casques doivent être synchronisés avec leurs sens visuels. Vous ne pouvez pas entendre la voix de quelqu'un deux secondes après qu'il vous ait parlé. Cela signifie que les algorithmes neuronaux doivent traiter les sons en moins d'un centième de seconde"
En raison de cette contrainte de temps, le système d'audition sémantique doit traiter les sons sur un appareil tel qu'un smartphone connecté, plutôt que sur des serveurs en nuage plus robustes. En outre, comme les sons provenant de différentes directions arrivent dans les oreilles des personnes à des moments différents, le système doit préserver ces retards et d'autres indices spatiaux afin que les personnes puissent toujours percevoir de manière significative les sons dans leur environnement.
Testé dans des environnements tels que des bureaux, des rues et des parcs, le système a été capable d'extraire des sirènes, des gazouillis d'oiseaux, des alarmes et d'autres sons cibles, tout en supprimant tous les autres bruits du monde réel. Lorsque 22 participants ont évalué la sortie audio du système pour le son cible, ils ont déclaré qu'en moyenne la qualité s'était améliorée par rapport à l'enregistrement original. Dans certains cas, le système a eu du mal à faire la distinction entre des sons qui partagent de nombreuses propriétés, comme la musique vocale et la parole humaine. Les chercheurs notent que l'entraînement des modèles sur un plus grand nombre de données réelles pourrait améliorer ces résultats.
Les autres coauteurs de l'article sont Bandhav Veluri et Malek Itani, tous deux doctorants à l'Allen School de l'UW ; Justin Chan, qui a terminé cette recherche en tant que doctorant à l'Allen School et qui est maintenant à l'université Carnegie Mellon ; et Takuya Yoshioka, directeur de la recherche à AssemblyAI.
Pour plus d'informations, contactez [email protected].

