CheckMag | Pas de GPU, pas de problème. Héberger votre propre LLM est infiniment plus amusant que les offres censurées des grands acteurs et fonctionne étonnamment bien.

Personne ne sait ce qu'il advient de vos données lorsque vous interrogez une IA, mais quoi qu'il en soit, elles ne vous appartiennent plus.
À côté de génération d'images et de vidéos, si vous souhaitez expérimenter les grands modèles de langage (LLM), mais que vous ne voulez pas confier vos données aux grandes entreprises, il est étonnamment facile d'héberger votre propre modèle, qui présente plusieurs avantages par rapport aux grands acteurs.
Tout d'abord, quoi que vous choisissiez d'en faire, toutes vos données restent sous votre contrôle, ce qui, si vous ne souhaitez pas les confier à Mechahitler, est un avantage immédiatest un avantage immédiat. Vous pouvez également utiliser pratiquement n'importe quel modèle, qu'il s'agisse de Deepseek, Gemma2 ou GPT, avec l'avantage supplémentaire de pouvoir utiliser des versions qui ne restreignent pas les types de requêtes que vous y lancez.
KoboldCPP est un outil de génération de texte d'IA facile à utiliser et exécutable une seule fois, conçu pour exécuter les grands modèles de langage GGUF et GGML. Il prend en charge à la fois le GPU et le CPU et peut agir comme un backend spécialisé pour les récits et les discussions d'IA. KoboldCPP peut être téléchargé à partir de GitHub ici et est disponible pour Windows, Linux, Mac ou Docker.
L'hébergement dans un conteneur permet d'exposer le LLM à tous les appareils de votre réseau, et il existe des modèles préconstruits pour les principales plateformes, y compris Unraid et TrueNAS. La même chose peut être réalisée avec d'autres installations tant que vous ajoutez les règles nécessaires à votre pare-feu.
Pour commencer
Une fois que vous avez choisi la plateforme de votre choix, vous devez déterminer le modèle à utiliser. Hugging Face est le meilleur endroit pour trouver des modèles, et ils doivent être au format GGUF.
Si vous prévoyez d'héberger des scénarios de D&D, vous voudrez certainement un modèle non censuré, sinon le LLM refusera finalement de faire du mal à l'un ou l'autre des personnages, ce qui peut générer des résultats indésirables indésirables.
Certains modèles, tels que Deepseek et Claudeont une propension à "penser", ce qui revient à cracher tout le processus de pensée de votre requête. Cela peut être acceptable avec un GPU qui fait le gros du travail, mais sans GPU, le processus est considérablement ralenti. Vous devrez expérimenter avec les modèles pour trouver celui qui vous convient, mais Gemma2 est un bon point de départ.
Trouvez la page des fichiers et copiez l'URL qui renvoie au fichier GGUF. De nombreux modèles ont plusieurs tailles, vous devrez donc en choisir un qui corresponde aux limites de votre mémoire vive.
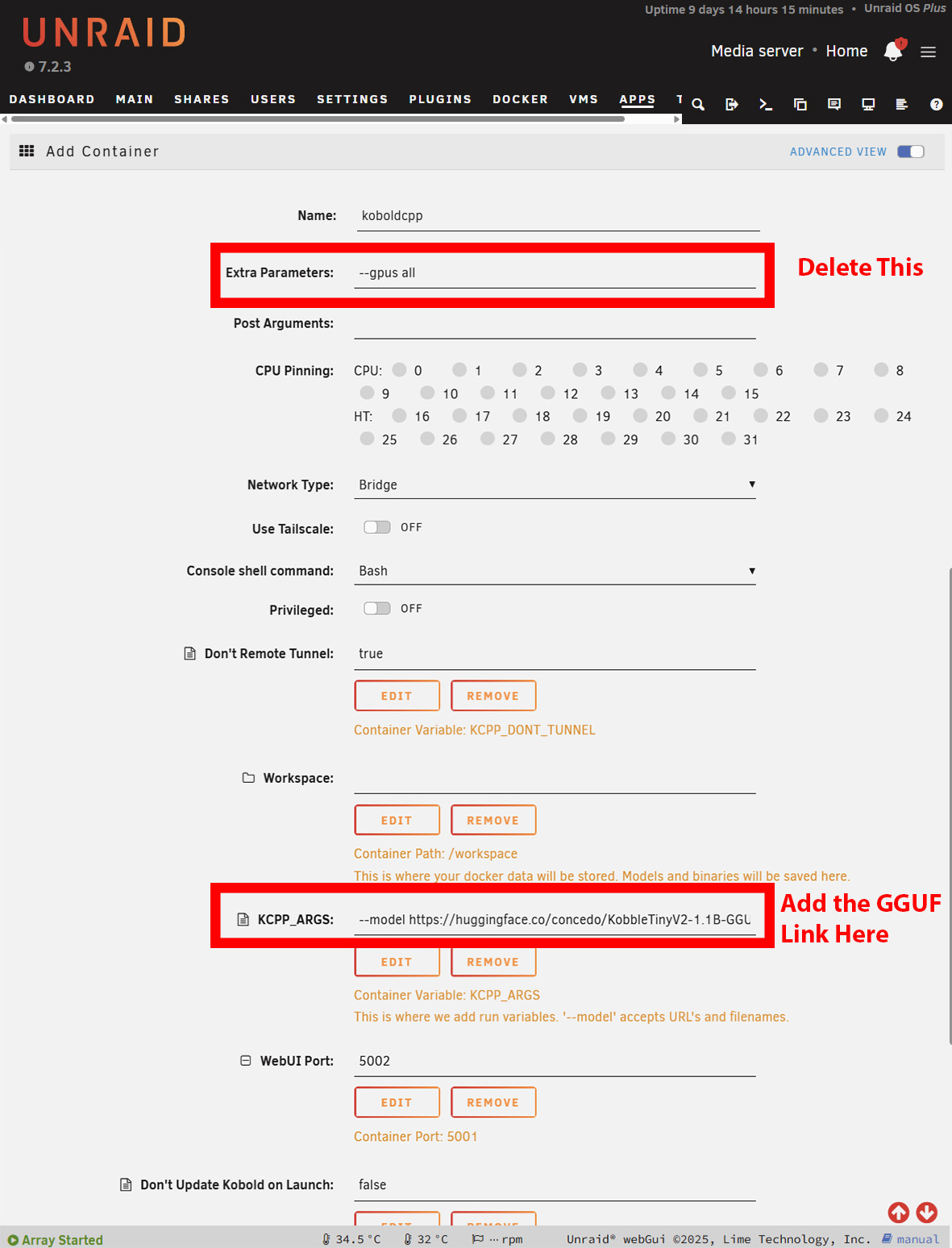
L'installation sous Windows est en grande partie la même. Cependant, vous devrez télécharger la version NoCUDA si vous l'utilisez sans GPU. Le démarrage peut prendre un certain temps, car KoboldCPP télécharge le modèle avant de vous présenter l'interface. Sous Windows, c'est évident, mais sur Unraid ou TrueNAS, vous devrez ouvrir les logs pour voir la progression du téléchargement. Sur Unraid, il se peut que vous deviez augmenter le stockage disponible des conteneurs Docker le stockage disponible des conteneurs Docker en fonction de la taille du modèle que vous avez choisi.
KoboldCPP offre 4 modes d'interface différents, y compris l'instruction, l'histoire, le chat et l'aventure.
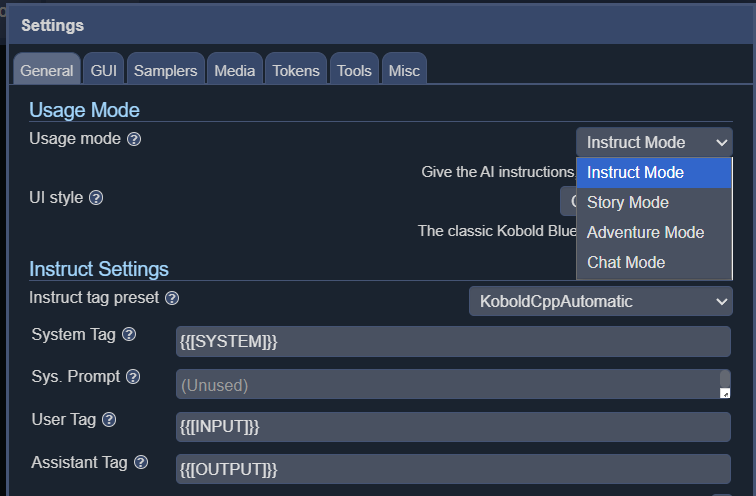
Bien qu'il ne soit pas le plus rapide, le texte est généré légèrement plus lentement que la vitesse de lecture moyenne. Parfaitement utilisable pour les scénarios de D&D sur un AMD 5950x à 16 cœurs(disponible sur Amazon), il fonctionnera probablement plus rapidement sur des processeurs plus modernes. Plus il y a de cœurs, mieux c'est, et une quantité décente de RAM vous permettra de faire tourner des modèles plus importants, bien que vous devriez vous contenter de 16 Go. La taille et le type de modèle auront également un impact significatif sur la vitesse de génération, et le choix d'un modèle plus léger peut augmenter considérablement la vitesse globale.
Cependant, si vous souhaitez essayer d'héberger vos propres modèles, en contournant les restrictions ou les implications en matière de confidentialité des données de ChatGPT, Claude ou Gemini, vous n'avez pas besoin d'un matériel sophistiqué pour commencer et vous pouvez toujours obtenir une expérience décente.
Source(s)

