Une langue surprenante bat l'anglais et le chinois dans les tests LLM, selon une nouvelle étude universitaire
Une nouvelle étude multilingue qui évalue la manière dont les modèles de langage de grande taille traitent les longs documents a permis de recueillir des informations inattendues : Le polonais, et non l'anglais ou le chinois, présente la plus grande précision lorsque les fenêtres contextuelles s'étendent jusqu'à 64 000 tokens et plus. Ces résultats proviennent de l'étude comparative OneRuler ( ), présentée dans un article de COLM 2025qui a testé 26 langues dans le cadre de tâches de recherche et d'agrégation.
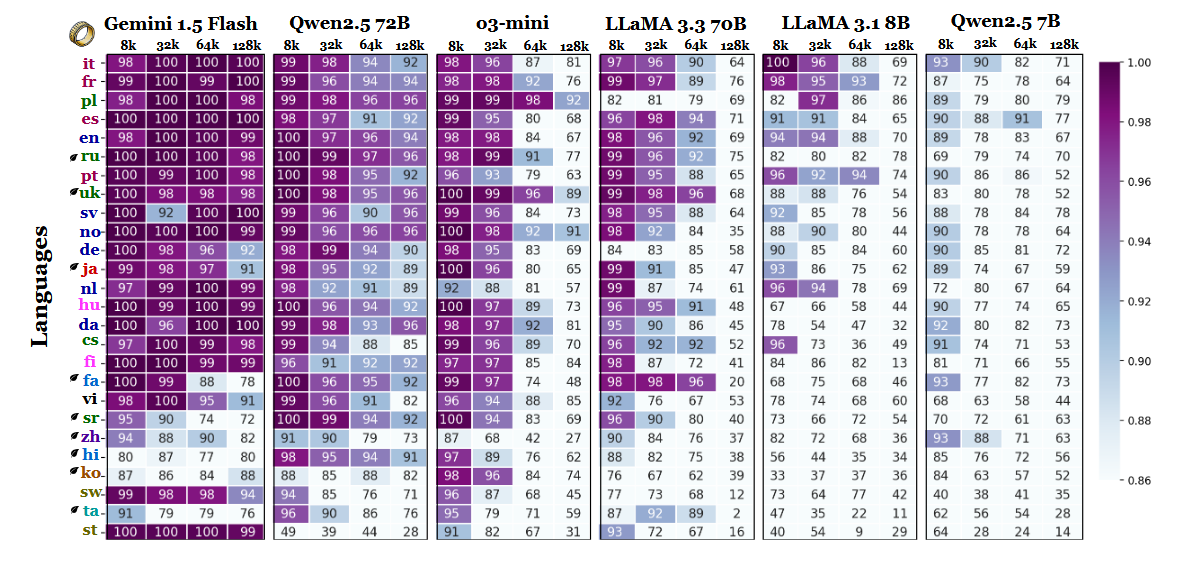
Les chercheurs ont comparé la précision des modèles à différentes longueurs de contexte et ont constaté une nette évolution lorsque les séquences devenaient plus longues. Selon le tableau des résultats (page 6), le polonais est en tête de toutes les langues avec une précision moyenne de 88 % à des échelles de contexte longues. L'anglais est relégué à la sixième place et le chinois se classe parmi les quatre dernières.
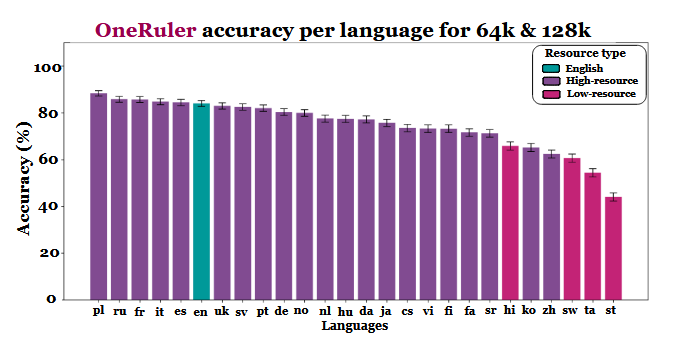
L'étude laisse entendre que cette disparité pourrait être liée à l'efficacité de la tokenisation et aux différences d'écriture plutôt qu'au simple volume de données d'entraînement. Les langues utilisant des écritures latines - comme le polonais, le français et l'espagnol - ont systématiquement obtenu de meilleurs résultats que celles qui utilisent des systèmes d'écriture logographique ou abugida. Le chinois, le coréen, le tamoul et d'autres langues n'ont montré qu'une précision modérée, même dans des contextes plus courts (et leur précision s'est encore détériorée à mesure que les séquences devenaient plus longues). Il est intéressant de constater que les classements attendus sont complètement inversés, car la plupart des LLM largement déployés sont formés principalement sur des ensembles de données à forte teneur en anglais. Pourtant, les résultats de l'article indiquent que lorsque les modèles doivent rechercher, rappeler ou résumer des informations enfouies dans de longs documents, les aspects structurels de la langue l'emportent sur la prévalence de l'ensemble de données.
D'autres résultats de l'étude comparative soutiennent également cette interprétation. L'écart de performance entre les langues les plus fortes et les plus faibles augmente fortement à mesure que le contexte s'élargit, passant de 11 % à 8 000 tokens à 34 % à 128 000 tokens. Un autre détail de l'étude montre à quel point ces tests peuvent être sensibles à de petites modifications des instructions. Par exemple, le simple fait d'autoriser le modèle à répondre "none" en cas d'absence d'une chaîne cible a fait chuter la précision en anglais de 32 % à 128 000 tokens, comme on peut le voir à la page 2.
Bien que le benchmark compare également les familles de modèles, les résultats impliquent que l'évaluation des contextes longs ne peut pas reposer uniquement sur les tests en anglais et que les généralisations des performances entre les langues peuvent être trompeuses si les effets du script et de la tokenisation sont ignorés. Au fur et à mesure que les fenêtres contextuelles s'agrandissent, les différences linguistiques deviennent plus importantes, et non moins importantes - et la domination de l'anglais dans les benchmarks LLM pourrait ne plus être représentative une fois que les longueurs de séquences atteindront des dizaines de milliers.
Source(s)
Une seule règle pour les mesurer tous : évaluation comparative des modèles linguistiques multilingues à contexte long au COLM 2025
Image principale par Zulfugar Karimov sur Unsplash

